class GetTextCB(Callback):
async def after_visit(self, crawler, idx):
if crawler.pages[idx].url == 'https://fastcore.fast.ai/':
loc = await crawler.pages[idx].find_ele('//span[contains(text(), "Welcome to fastcore")]')
if loc:
assert await loc[0].get_text() == "Welcome to fastcore"
C = Crawl(2, ['https://solveit.fast.ai/', 'https://fastcore.fast.ai/'], [GetTextCB()])
await C.run(headless=False)crawler
crawler with call backs
Web Crawler with Callback System
This crawler implements a flexible web scraping system with callback hooks for extensibility, inspired by fastai’s callback system.
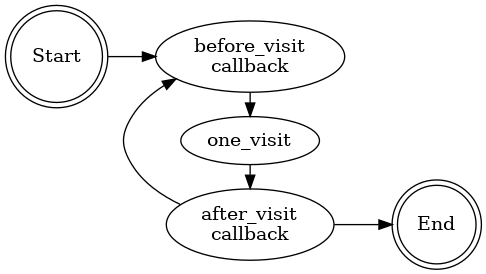 ## Architecture The crawler operates with two main callback hooks:
## Architecture The crawler operates with two main callback hooks: before_visit and after_visit, with an ord parameter controlling execution order.
Key Features
- Parallel Processing:
- Configurable number of pages (
np) for concurrent processing - Efficient browser resource management
- Configurable number of pages (
- URL Management:
- Input: List of URLs to visit (
to_visit) - Tracks progress through callback-accessible sets:
visited: Already processed URLsunvisited: Pending URLsvisit_window: Current batch of URLs (size =np)
- Input: List of URLs to visit (
- Callback System:
- Extensible through custom callbacks
- Ordered execution (
ord) - Full access to crawler state
Crawl
Crawl (np:int=1, to_visit:Optional[List[str]]=None, cbs=None)
Initialize self. See help(type(self)) for accurate signature.
| Type | Default | Details | |
|---|---|---|---|
| np | int | 1 | |
| to_visit | Optional | None | |
| cbs | NoneType | None | type: ignore |
callback
extract text for a given xpath
To traverse all webpages within the same domain using
TraveseSameDomainCB
TraveseSameDomainCB (url)
Callback helping traveling all the links available in the same domain.
url = 'https://solveit.fast.ai/'
C = Crawl(5, [url], [TraveseSameDomainCB(url)])
await C.run(headless=True)
assert all([domain(i)==domain(url) for i in C.visited])
assert len(C.unvisited) == 0Crawl a url and save in md
ToMDCB
ToMDCB (base_dir='PW')
Callback helping traveling all the links available in the same domain.
url = 'https://solveit.fast.ai/'
C = Crawl(3, [url], [TraveseSameDomainCB(url), ToMDCB()])
await C.run(headless=False)writing to fn=Path('PW/solveit_fast_ai/index.md')
writing to fn=Path('PW/solveit_fast_ai_privacy/index.md')
writing to fn=Path('PW/solveit_fast_ai_course_info/index.md')
writing to fn=Path('PW/solveit_fast_ai_terms/index.md')
writing to fn=Path('PW/solveit_fast_ai_learn_more/index.md')